QRC Technologies’ Focus On AI Transfer Learning And AI Transparency In EMS Survey

In our previous article, we outlined the Artificial Intelligence (AI) Ethical Guidelines promoted by the Department of Defense and the Intelligence Community (DoD/IC) and described QRC’s technical approach to compliance. Here, in part three of our series, we will review how most AI systems learn and what the ramifications are for our ability to trust the system’s behavior.
The Need For AI In Electromagnetic Spectrum Operations
To review some information from our previous article, new communications technologies have made the electromagnetic spectrum (EMS) an increasingly dynamic environment. The expansion of cellular data transfer capabilities, the adoption of wireless Internet of Things (IoT) sensors, and the widespread introduction of self-driving/unmanned vehicles have resulted in a monumental increase in systems’ and stakeholders’ reliance on wireless communication.
Accordingly, EMS domain situational awareness is growing in complexity, requiring systems that are increasingly dynamic and intelligent. As waveform complexity increases, legacy approaches such as manually monitoring the EMS for emitters have increasing limitations. Thus the trend toward increasing use of AI/ML in EMS survey.
What Is Machine Learning In The Context Of Artificial Intelligence?
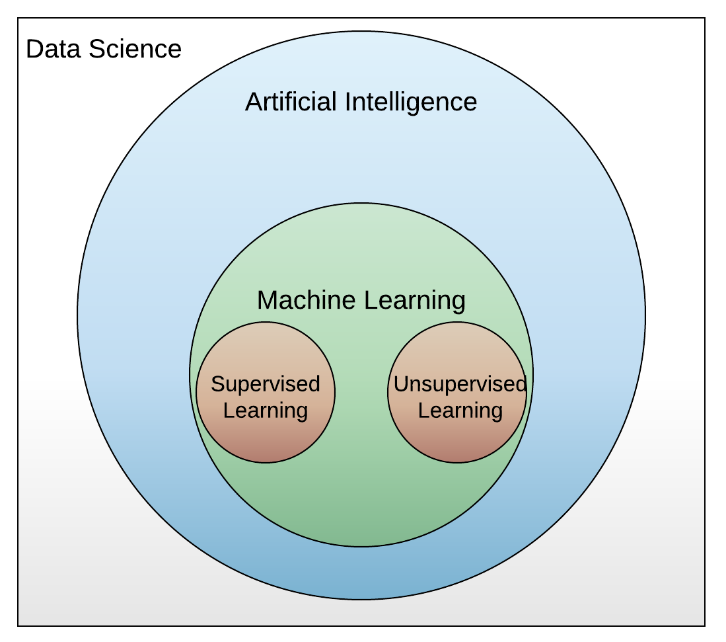
Machine learning (ML) is a subset of AI. It incorporates algorithms and statistical models that computer systems use to perform a specific task without the need for programmed instructions. This is in contrast to traditional programming that requires defined inputs and outputs. Instead, ML relies on patterns and inference from the data to make decisions.
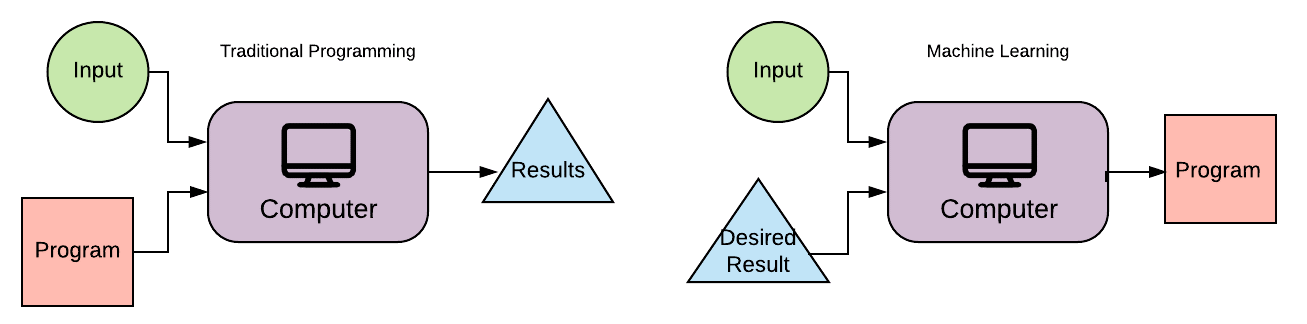
For simple traditional programming tasks, the user programs algorithms which instructs the computer how to execute the steps required to solve the problem. For advanced tasks, such as continuous EMS monitoring, it is challenging for humans to program the algorithms necessary to identify every signal, especially new signals, in a timely manner. Instead, ML algorithms build a mathematical model based on sample data, known as “training data,” in order to make predictions or decisions without being explicitly programmed to perform the task. Machine learning employs various approaches to teach computers to accomplish tasks in situations where traditional algorithms are not available or are difficult to create.
What Are The Major Categories Of AI Learning?
AI/ML is traditionally divided into three broad categories, depending on the nature of the data and input available to the system:
- Supervised learning: The computer is given example inputs and their desired outputs, provided by a “teacher,” and the goal is for the system to learn a general rule that maps inputs to outputs.
- Unsupervised learning: No labels are given to the learning algorithm, leaving the system on its own to find structure to the inputs it is given.
- Reinforcement learning: A computer program interacts with a dynamic environment in which it must perform a certain goal (such as playing chess against an opponent). As the system navigates the problem space, the program is provided feedback by the “teacher” that is analogous to rewarding it, therefore reinforcing desired outcomes.
Other approaches have been developed which do not fit neatly into this categorization. In addition, many variations of ML are introduced frequently by practitioners. These are beyond the scope of this article. Here we will focus our discussion on supervised and unsupervised learning.
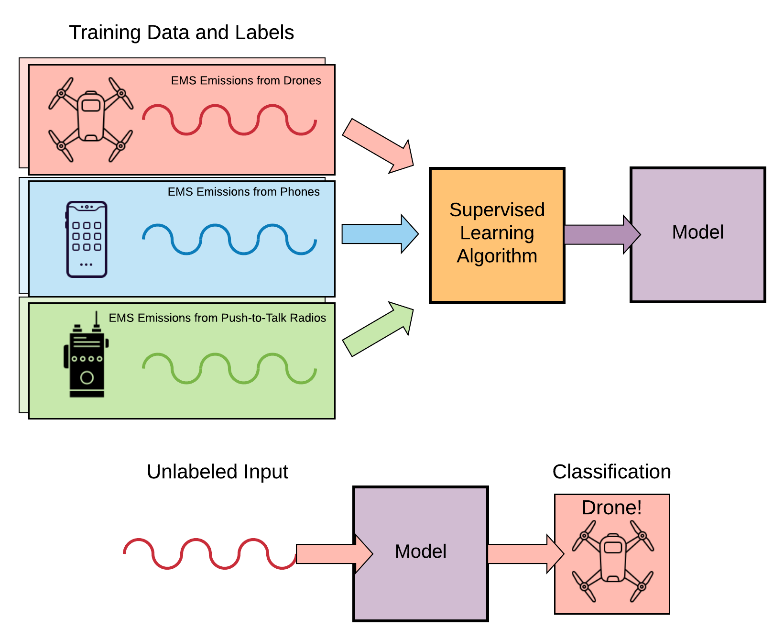
Supervised Learning:
Supervised learning algorithms build a mathematical model of a set of data that contains both the inputs and the desired outputs. The data is known as “training” data, and it consists of a set of training examples. Each training example has one or more inputs and the desired output. In the mathematical model, each training example is represented by an array or vector, and the training data is represented by a matrix. Through iterative steps, supervised algorithms learn a function that can be used to predict the output associated with new inputs. An algorithm that improves the accuracy of its outputs or predictions over time is said to have learned to perform that task.
Supervised learning algorithms generally fall into two categories: classification and regression. Classification algorithms are used when the outputs are restricted to a limited set of values. Regression algorithms are used when the outputs may have any numerical value within a range. Of note, similarity learning is an area of supervised ML closely related to regression and classification which employs a similarity function that measures how similar or related two objects are. It has applications in visual identity tracking, face verification, and speaker verification.
One of the most popular and widespread methods to achieve supervised learning is Deep Learning. In Deep Learning, multiple layered configurations of artificial neurons (or “Neural Networks”) are used to find hidden high dimensional relationships between variables. Although this method often requires vast amounts of data and computational expense to build models, the models are generally efficient when deployed, not requiring a great deal of computation to achieve classification capability. However, a drawback of using Neural Network based models for classification is that the model’s “reasons” for choosing one category over another are not easily discernable without access to the training data.
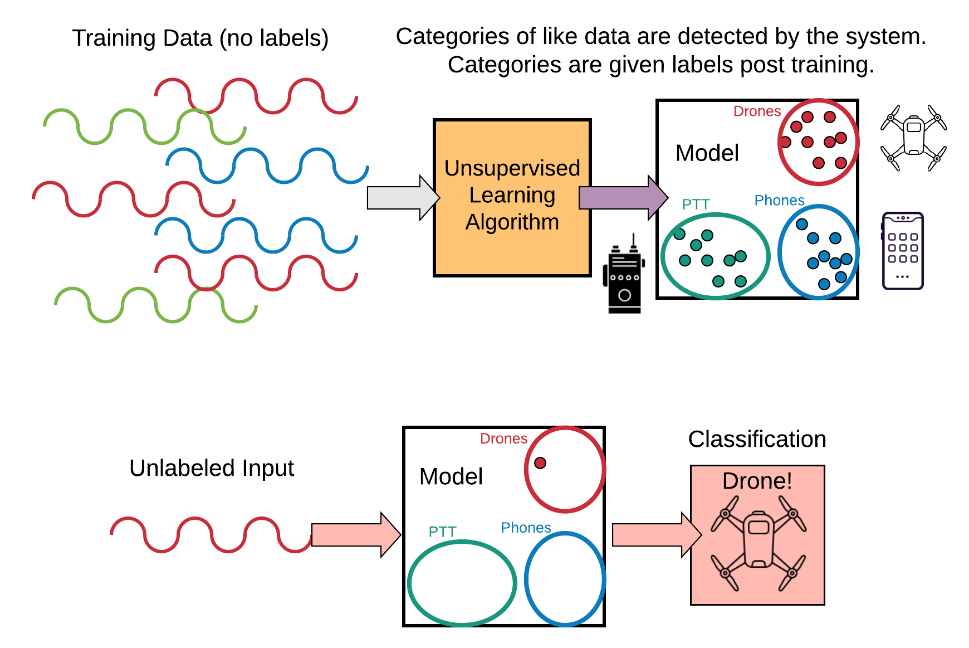
Unsupervised Learning:
Unsupervised learning algorithms take input data and create structure out of the data, such as grouping or clustering. The algorithms learn from test data that has not been labeled, classified or categorized. Instead of responding to feedback, unsupervised learning algorithms identify commonalities in the data and react based on the presence or absence of such commonalities.
Cluster analysis (clustering) is a common form of unsupervised learning where learned categories (classes) are discovered via the assignment of sets of observations into subsets (called clusters). Observations within the same cluster are similar according to one or more predesignated criteria, while observations from different clusters are dissimilar. Although there are many methods of performing clustering, some of the most popular methods, such as K-means or DBSCAN clustering make use of Euclidean geometry to assemble clusters from a collection of input values.
What Is Transfer Learning?
Transfer learning is the process of using or allowing one AI/ML model to teach another model what it knows, in order to apply that learning in a different context or environment. Although there are various methods of achieving this within deep learning systems, transfer learning is generally easier to achieve in models where the input features going into the decision-making are well understood. In these situations, such “teaching” can require little data, allowing outputs to be shared or combined between multiple systems in near real time. In practical terms, the shared learning can be performed either automatically, through the network, or through manual synchronization.
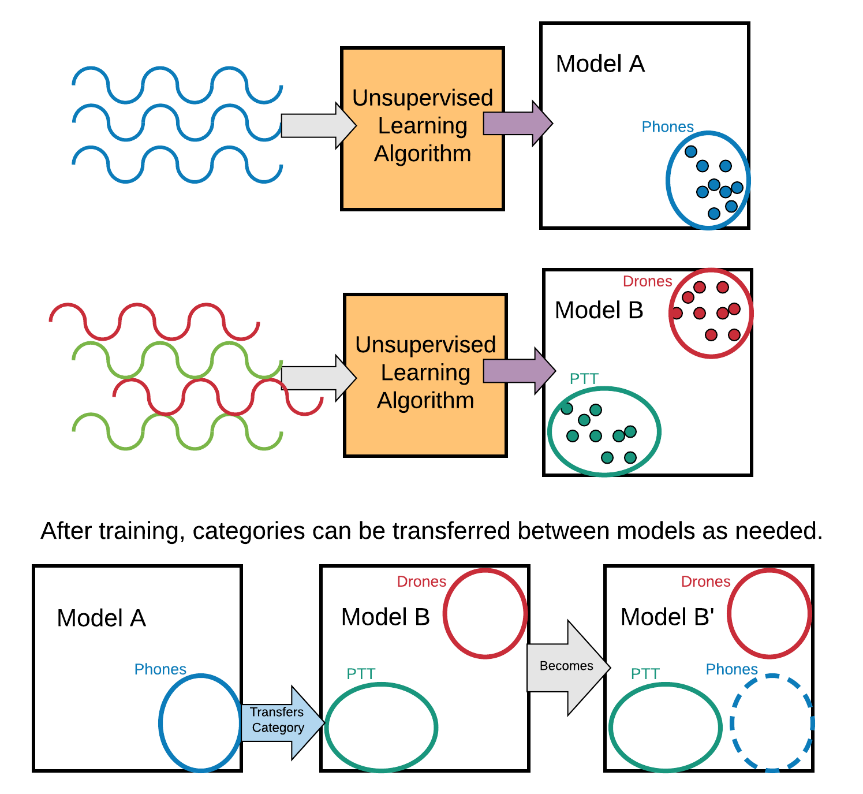
Comparing And Contrasting Learning Methods In EMS Survey
What are the pluses and minuses associated with traditional programming, supervised deep learning, and unsupervised clustering techniques as applied to EMS survey?
In traditional programming, a lookup-table-based methodology is typically employed. The lookup table is populated with carefully measured, observed signal characteristics, and those are compared to the incoming signal (data). On the plus side, the methodology is simple in execution, does not involve much complexity, does not require much computational load, is easily explainable and understood by the average user, and is process driven from a software engineering perspective. On the minus side, the methodology requires specialized talents and resources to generate and maintain the lookup table, and it can be a bit rigid in terms of classification. The static model (look up table) does not learn from its environment, so the lookup table must be constantly revised to keep up with new signals that are being broadcast.
In a supervised, deep learning scenario, the emphasis is on letting the system do all the work. On the plus side, the neural networks used in this method accommodate deviations in signal sources, require very little subject matter expertise to employ, and are able to draw from refinements taking place within the industry and academia. On the minus side, supervised learning requires a lot of training data in order to adequately train the model; the learning process is sensitive to the quality of the RF portion of the system; and it can consume a lot of computing power. In most cases, system updates require full retraining of each system. The ability to share learned behaviors between individual systems (transfer learning) can be difficult. A big problem is that models created by deep learning can often be undecipherable and can generate somewhat unexplainable and hard-to-trust answers. We call this the “opaque box” of deep learning.
In clustering-based, unsupervised learning approaches, the methodology tends to take on a more balanced approach between data science and the subject matter expertise of the programmer or operator. It takes the form of unsupervised learning algorithms that are coupled with specific features that are identified by the subject matter experts. On the plus side, there is very little data needed for teaching. The algorithms are both hardware agnostic and problem space agnostic. Because the system can accommodate the variability present within the RF environment, it can learn within this environment. Transfer learning between individual systems is straightforward and allows for multiple models from different systems to be rapidly combined. Most importantly, the models generated are understandable to humans. We call this the “transparent box” of unsupervised cluster learning. On the minus side, subject matter expertise in signal processing is needed for the initial feature definition phase.
What Is Ethical AI?
Because AI can influence our perception of the world and our decision-making, there is growing recognition that the discussion and practice of AI should include considerations regarding AI ethics. It is important to recognize that when humans devise AI autonomous and decision support systems, accountability does not shift to the systems in question, but remains with the human beings that create and use the systems.
How do we deploy trustworthy AI/ML systems that are in line with the values of the individuals and organizations using them? We need to be able to trust the soundness of five aspects of an AI system:
- The learning methods, which transform training data into models used for further decision-making
- The data, which serves as the basis for decisions that are made during system runtime
- The perception of the system, to accurately assess the current state by which decisions are made
- The execution of the system, where actions are taken by the system because it arrives at decisions in a responsible manner
- The security of the system, in cyber terms and in model, data, and algorithmic terms
QRC’s Approach To AI/ML Emphasizes Transfer Learning, Transparency, And Ethical AI
QRC employs and develops transparent-box approaches to AI development based on the unsupervised learning model. Our development of AI/ML-based capability starts with subject matter expertise in the EMS. Data is explored using a combination of statistical methods to develop well-defined and distinguishable features. Once the feature set is developed, unsupervised learning techniques are applied, creating a system that has a transparent model at its core. One of the benefits of the QRC approach is transfer learning capability, the ability of the system to share its learned EMS signal information with other systems. The learned signals files that are created are on the order of kilobytes (kB), that can be easily transferred between units over low bandwidth communications (e.g. wireless mesh networks) as well as by physical means of file transfer.
QRC is committed to developing systems that meet or exceed the current understanding of AI/ML ethics. In addition to the DoD/IC guidelines, our development culture incorporates a three-fold approach:
- Transparent – The training data is transparent and readily inspectable. We can trace how a model learns from data and can fully account for the reasoning behind the decisions made by a system.
- Understandable – We understand the RF survey data itself and the circumstances in which it was gathered, curated, and labeled. We also understand why the model made the decision that it did, based on the data provided.
- Auditable – The system must produce detailed logs to allow humans to assess correct perception and execution.
QRC Technologies is dedicated to applying AI/ML best practices and fundamental research to integrate ethically sound autonomous capabilities into solutions that characterize, control, and dominate the EMS.